
Understanding Neural Networks: The Backbone of AI
Have you ever wondered how your smartphone recognizes your face,
Understanding Neural Networks: The Backbone of AI Read Post »
Have you ever wondered how your smartphone recognizes your face,
Understanding Neural Networks: The Backbone of AI Read Post »

Generative AI is transforming the world as we know it,
Pioneers of Generative AI: Meet the Inventors Read Post »
Unlocking the Magic: Key Definitions and Concepts in Generative AI
Key Definitions and Concepts in Generative AI Read Post »
Imagine a world where machines can create art, compose music,
The History of Generative AI: From Concept to Reality Read Post »
Welcome to the final blog in our “Introduction to Machine
Setting Up a Simple ML Project: Tools and Platforms Read Post »
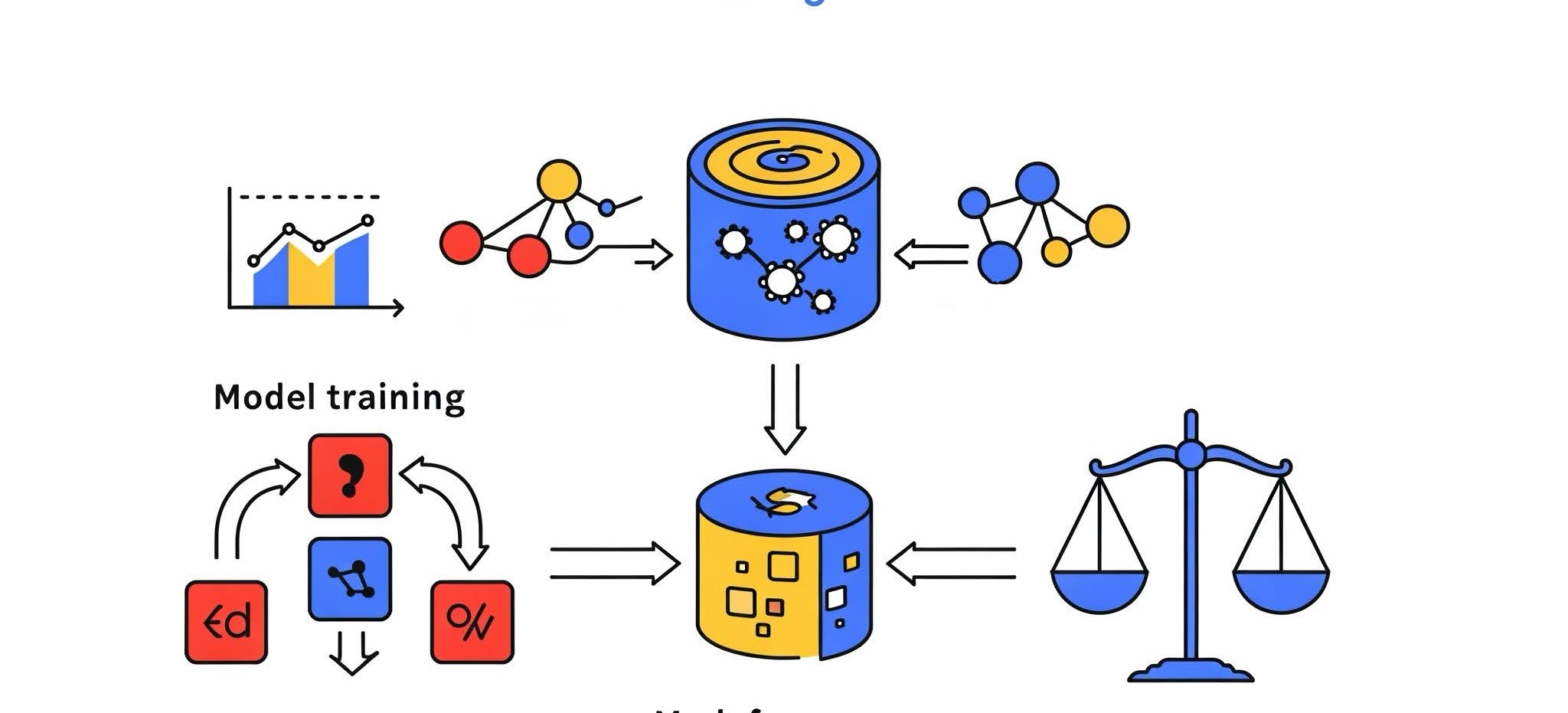
Artificial Intelligence (AI) and Machine Learning (ML) are revolutionizing industries
Introduction to Model Training and Evaluation. Challenges in AI and Machine Learning Read Post »
How AI is Transforming Industries: The Role of Data in
AI is Transforming Industries: The Role of Data in Machine Learning Read Post »

Artificial Intelligence (AI) has come a long way since its
History of AI: From Turing to Modern ML & Types of Machine Learning Algorithms Read Post »